Week 2 of the Data Engineering Zoomcamp focused on workflow orchestration using Mage.ai.
Orchestration involves coordinating numerous tasks to run quickly and efficiently.
The process began with extracting data from the New York Taxi sample dataset, transforming it for clarity and usefulness, and finally exporting it to both a PostgreSQL database and a Google Cloud Storage bucket.
Configuring Mage
The initial setup involves cloning the Mage Zoomcamp repository and starting the Docker container.
docker-compose build
docker-compose up
Building an ETL Pipeline with Mage (PostgreSQL)
Mage has components that make code highly reusable (called Blocks). There are three types of blocks you can use when creating a pipeline:
- Data Loader
- Transformer
- Data Exporter
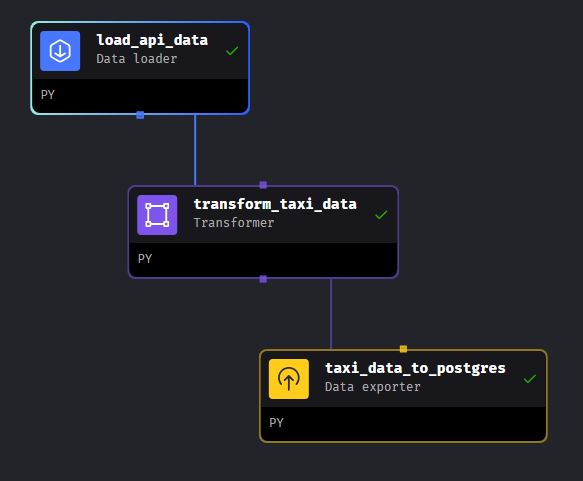
The first pipeline I built is an ETL pipeline using blocks to load the yellow taxi data from a URL, transform the data, and export it into a PostgreSQL database within my Docker container.
For this, I had to set up a YAML profile (called ‘dev’ in this case) in the io_config.yml file. The following code block utilizes environmental variables from the .env file.
dev:
POSTGRES_CONNECT_TIMEOUT: 10
POSTGRES_DBNAME: ""
POSTGRES_SCHEMA: ""
POSTGRES_USER: ""
POSTGRES_PASSWORD: ""
POSTGRES_HOST: ""
POSTGRES_PORT: ""
Data Loader
Now it’s time to create the first data loader block. This one loads a CSV file with New York taxi data.
In the dictionary object ‘taxi_dtypes,’ the data types are defined before the transformation.
The next variable, ‘parse_dates_yellow_taxi,’ is a list of date columns to be parsed.
To read ‘tpep_pickup_datetime’ and ‘tpep_dropoff_datetime’ correctly, I used the parse_dates parameter to automatically detect and parse these formats into Python datetime objects.
If you attempt to parse datetime columns as datetime64 datatypes in ‘taxi_dtypes,’ it will throw an error.
# Import necessary libraries
import io
import pandas as pd
import requests
# Check if 'data_loader' and 'test' are not already defined in the global scope
if 'data_loader' not in globals():
from mage_ai.data_preparation.decorators import data_loader
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
# Define a data loader function using the 'data_loader' decorator
@data_loader
def load_data_from_api(*args, **kwargs):
# URL for the Yellow Taxi dataset
url_yellow_taxi = 'https://github.com/DataTalksClub/nyc-tlc-data/releases/download/yellow/yellow_tripdata_2021-01.csv.gz'
# Define data types for specific columns in the dataset
taxi_dtypes = {
'VendorID': 'Int64',
'store_and_fwd_flag': 'str',
'RatecodeID': 'Int64',
'PULocationID': 'Int64',
'DOLocationID': 'Int64',
'passenger_count': 'Int64',
'trip_distance': 'float64',
'fare_amount': 'float64',
'extra': 'float64',
'mta_tax': 'float64',
'tip_amount': 'float64',
'tolls_amount': 'float64',
'ehail_fee': 'float64',
'improvement_surcharge': 'float64',
'total_amount': 'float64',
'payment_type': 'float64',
'trip_type': 'float64',
'congestion_surcharge': 'float64'
}
# Columns to be parsed as datetime objects
parse_yellow_taxi = ['tpep_pickup_datetime', 'tpep_dropoff_datetime']
# Read data from the specified URL using pandas read_csv function
return pd.read_csv(url_yellow_taxi, sep=',', compression='gzip', dtype=taxi_dtypes, parse_dates=parse_yellow_taxi)
# Define a test function using the 'test' decorator
@test
def test_output(output, *args) -> None:
# Assert that the output is not None
assert output is not None, 'The output is undefined'
The next step is to transform the loaded data, addressing some special cases.
The key transformation here is ‘non_zero_passengers,’ which essentially filters out any row in the dataset where the passenger count is zero.
It also performs a count on the number of records where the ‘passenger_count’ is not zero in the ‘non_zero_passengers_count’ dataframe.
The ‘non_zero_passenger’ dataframe is then returned to be passed to the Data Exporter block.
# Check if 'transformer' and 'test' are not already defined in the global scope
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
# Import necessary libraries
import pandas as pd
# Define a transformer function using the 'transformer' decorator
@transformer
def transform(data, *args, **kwargs):
# Filter DataFrame for records with zero passengers
zero_passengers = data[data['passenger_count'].isin([0])]
zero_passengers_count = zero_passengers['passenger_count'].count()
# Filter DataFrame for records with one or more passengers
non_zero_passengers = data[data['passenger_count'] > 0]
non_zero_passengers_count = non_zero_passengers['passenger_count'].count()
# Print preprocessing information
print(f'Preprocessing: records with zero passengers: {zero_passengers_count}')
print(f'Preprocessing: records with 1 passenger or more: {non_zero_passengers_count}')
# Return the transformed DataFrame with non-zero passenger counts
return non_zero_passengers
# Define a test function using the 'test' decorator
@test
def test_output(output, *args) -> None:
# Assert that there are no rides with zero passengers in the transformed output
assert output['passenger_count'].isin([0]).sum() == 0, 'There are rides with zero passengers'
Data Exporter
In the final step is time to export the data. I added a Data Exporter block similair to how I added our data loader and transformer.
In this data exporter, I defined four variables:
- schema_name
- table_name
- config_path
- config_profile
schema_name and table_name will be later used to query the postgreSQL database.
SELECT * FROM ny_taxi.yellow_taxi_data
Setting the ‘config_profile’ to ‘dev’ instead of ‘default’ allows access to the ‘dev’ profile in the io_config.yaml file, where the PostgreSQL connection details were previously defined.
For insight into the Mage GUI, here’s a screenshot:
# Import necessary libraries and modules
from mage_ai.settings.repo import get_repo_path
from mage_ai.io.config import ConfigFileLoader
from mage_ai.io.postgres import Postgres
from pandas import DataFrame
from os import path
# Check if 'data_exporter' is not already defined in the global scope
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
# Define a data exporter function using the 'data_exporter' decorator
@data_exporter
def export_data_to_postgres(df: DataFrame, **kwargs) -> None:
# Specify the name of the schema to export data to
schema_name = 'ny_taxi'
# Specify the name of the table to export data to
table_name = 'yellow_taxi_data'
# Define the path to the configuration file
config_path = path.join(get_repo_path(), 'io_config.yaml')
# Specify the configuration profile
config_profile = 'dev'
# Use the Postgres class with a specified configuration to export data
with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader:
loader.export(
df,
schema_name,
table_name,
index=False, # Specifies whether to include index in exported table
if_exists='replace', # Specify resolution policy if the table name already exists
)
Now it’s time to execute the pipeline! This may take a few seconds to run due to the size of the dataset being ingested into PostgreSQL.
Building an ETL Pipeline with Mage (Google Cloud)
Moving forward in the Week 2 module, the task is to construct an ETL pipeline similar to the initial one.
The key distinction is that this time, I’ll be exporting the dataset to a Google Cloud Bucket instead of PostgreSQL.
To achieve this, a few additional steps need to be taken, as outlined below.
- Create a cloud storage account
- Create a service account
- Download JSON keys (additionally, it’s necessary to download a JSON key to authenticate with the new service account)
- Update Mage configuration (environmental variables):
- bucket_name
- object_key
- os.environ
- project_id
- bucket_name
- object_key
- table_name
When executing the pipeline, the CSV will be extracted from the URL, transformed as before, and loaded into my Google Cloud Storage Bucket using the parameterized Python script with assistance from the specified Google credentials.
In Summary
This week’s journey through the Data Engineering Zoomcamp has taken me deep into the heart of workflow orchestration with Mage. I’ve explored:
- Fundamentals of Workflow Orchestration: Understanding how Mage can orchestrate various tasks, processes, and data workflows to achieve a specific outcome.
- Building an ETL Pipeline: I walked through constructing an efficient ETL pipeline using Mage, emphasizing the integration with Python, PostgreSQL, and Google Cloud Storage for effective data handling.