
What is Spark?
Spark is a powerful tool for processing large amounts of data quickly.
Picture having a massive load of data to deal with. Spark steps in to help process all that data much faster than traditional methods.
Here’s how it works: Spark breaks down big data tasks into smaller chunks and spreads them out across several computers.
Then, it cleverly manages these pieces to ensure they’re processed efficiently and speedily.
What’s really neat about Spark is its versatility.
It can handle various data processing tasks, like analysing data, running machine learning algorithms, or dealing with streaming data in real-time.
It’s designed to be user-friendly, with easy-to-understand APIs that let you write code in languages like Python, Java, or Scala.
Thanks to its flexibility, scalability, and speed, Spark is a popular choice for batch processing tasks, from simple data transformations to complex analytics on huge datasets.
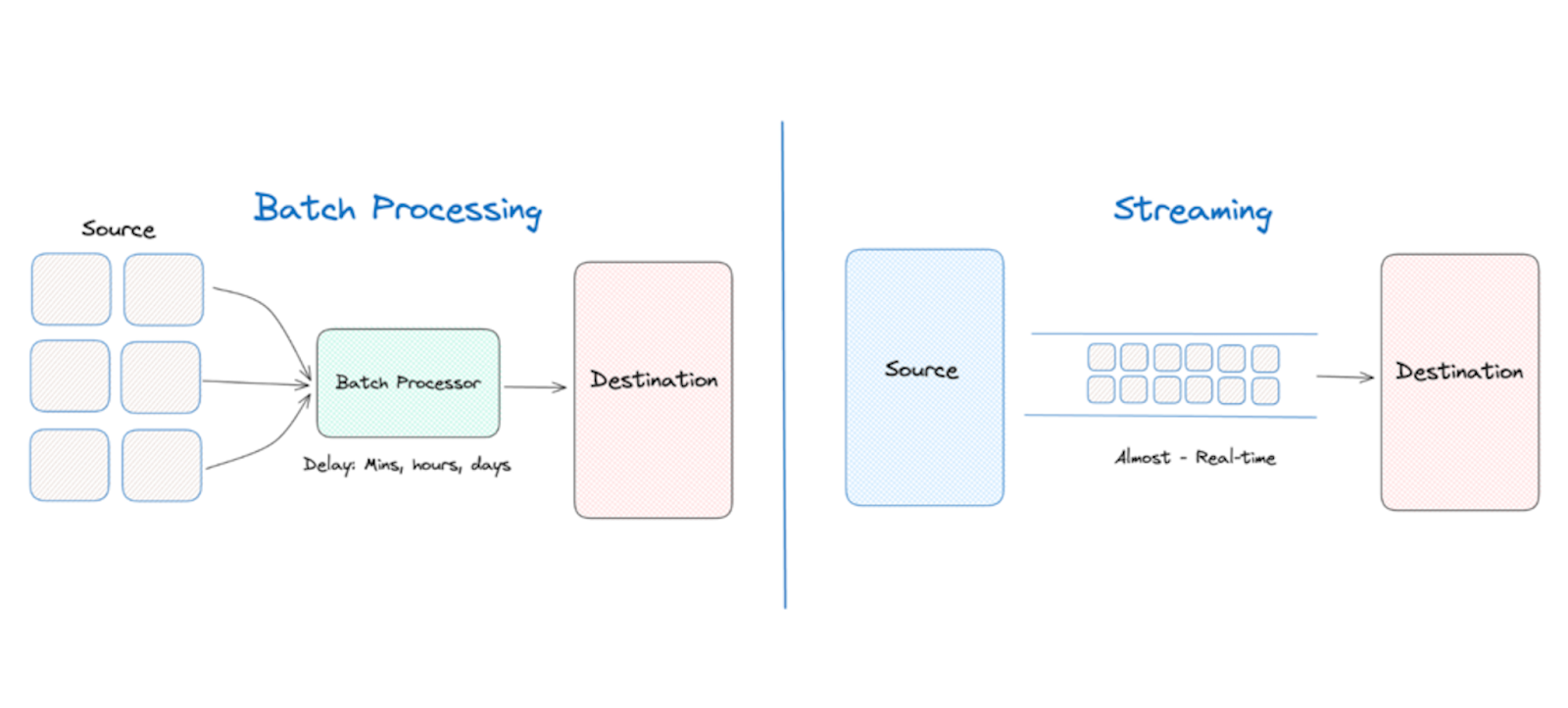
Batch processing vs Stream processing
Batch processing involves handling data in large chunks, much like preparing a big meal for the entire week.
You gather all your ingredients, cook them together, and serve the meal all at once.
It’s efficient for managing significant quantities of data, similar to cooking a massive pot of soup to last you through the week.
On the other hand, stream processing is comparable to operating a sandwich shop.
You make each sandwich as soon as the order comes in and serve it fresh.
It’s all about processing data in real-time, managing it as it flows in, just like preparing sandwiches to order for hungry customers.
Batch processing is suitable for dealing with large volumes of data at once, while stream processing is ideal for real-time data processing and responding to events as they happen.
Now, let’s zoom back into Spark and how it does batch processing.
First off, data ingestion. You’ll want to pull in data from various sources like files, databases or APIs.
Spark provides slick APIs for efficiently reading data from these sources.
Once your data’s in, it often needs to be transformed, cleaned or aggregated before analysis.
Spark provides a rich set of transformation functions (map, filter, groupBy, join, etc.) that can be applied to distributed datasets (RDDs or DataFrames) to perform these operations in parallel across a cluster of machines.
With the transformed data, you can perform various types of analyses, such as statistical analysis, machine learning, graph processing or SQL queries.
Spark provides libraries and APIs for these purposes, including Spark SQL for SQL-based queries, MLlib for machine learning, GraphX for graph processing and Spark Streaming for real-time analytics on batch data.
But Spark doesn’t stop there. It’s not just about getting the job done, it’s about doing it with finesse. It optimises execution, zips through tasks and minimises data shuffling for maximum efficiency.
Once your data’s been through the Spark treatment, it’s ready for its close-up. Results can be written back to storage for further analysis, reporting or visualisation. Spark plays nice with various output formats and systems, making sure your insights reach the right audience.
PySpark
PySpark is the Python API for Apache Spark, allowing developers to interact with Spark using Python.
It provides a Pythonic interface to Spark’s distributed data processing capabilities, making it easy to write Spark applications using Python code.
PySpark seamlessly integrates with other Spark components, opening up a world of possibilities.
Whether you’re crunching numbers, wrangling data, or training machine learning models, PySpark got your back. And the best part?
You can do it all from your favourite Python environment, be it Jupyter Notebooks or PyCharm.
Sure, Python might not be the speediest language out there, but with PySpark, you get the best of both worlds—Python’s simplicity and Spark’s horsepower.
In jupyter notebook or in python file I wrote this simple code:
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("local[*]") \
.appName('test') \
.getOrCreate()
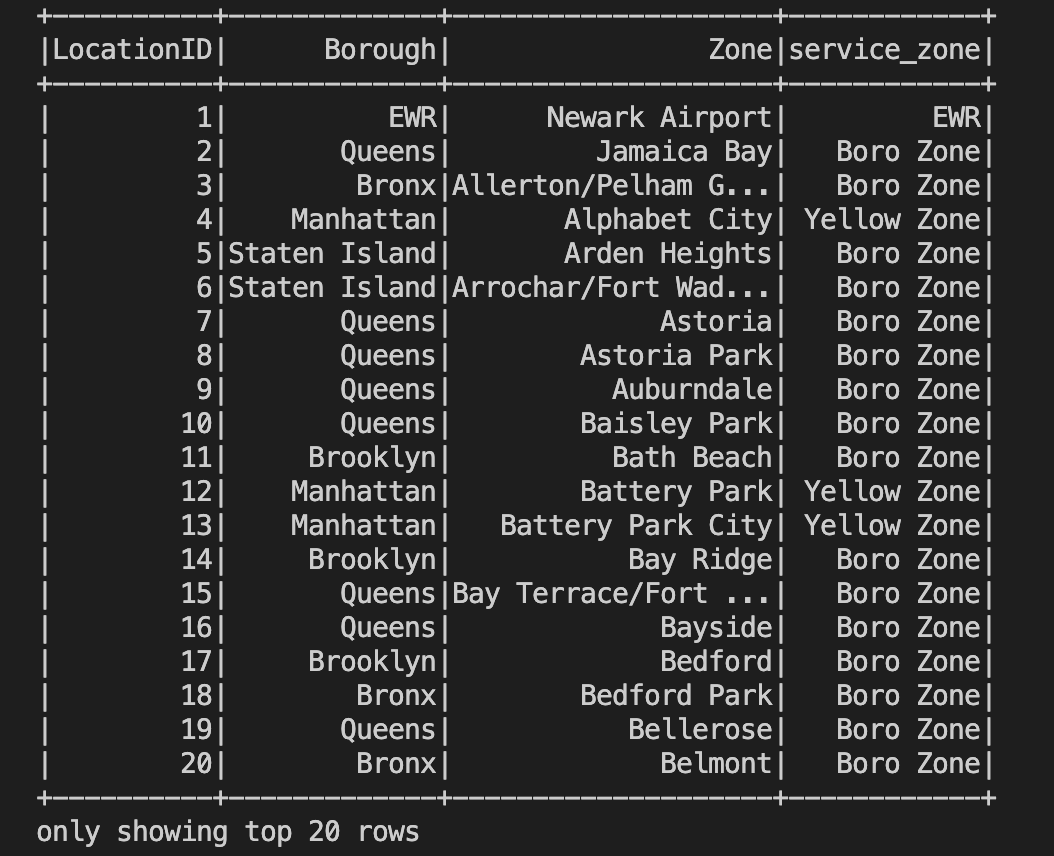
df = spark.read \
.option("header", "true") \
.csv('taxi+_zone_lookup.csv')
df.show()
And got this as a result:
RDDs (Resilient Distributed Datasets) and DataFrames
RDDs and DataFrames are two different abstractions for working with distributed data in Apache Spark, each with its own characteristics and use cases.
RDDs are like the Swiss Army knives of Spark—versatile, flexible and ready for anything. They’re your go-to for low-level data wrangling tasks, offering fine-grained control over your data.
On the other hand, DataFrames are the polished, refined cousins. They’re all about structure and organisation, giving you a tabular view of your data. With DataFrames, working with structured data feels like a walk in the park.
But which one should you choose? Well, it depends on your needs. If you’re dealing with unstructured data or need fine-grained control, RDDs are your best bet. But if structured data and ease of use are your priorities, DataFrames are the way to go.
There are two types of operations that you can perform on distributed datasets (RDDs, DataFrames, or Datasets). These operations enable you to manipulate, process, and analyse data in parallel across a cluster of machines. Here’s an explanation of transformations and actions:
Transformations:
- Transformations are operations that create a new distributed dataset (RDD, DataFrame, or Dataset) by applying a function to each element of the original dataset.
- Transformations are lazy, meaning they do not compute the result immediately. Instead, they build up a Directed Acyclic Graph (DAG) of transformations, representing the computation to be performed.
- Transformations are typically narrow or wide. Narrow transformations (e.g., map, filter) apply a function independently to each partition of the dataset, while wide transformations (e.g., groupByKey, join) may involve data shuffling and aggregation across partitions.
Examples of transformations include map, filter, flatMap, groupBy, join, union, distinct, sortBy, repartition, etc.
Actions:
- Actions are operations that trigger the execution of transformations and return a result to the driver program or write data to external storage.
- Actions are eager, meaning they compute the result immediately and initiate the execution of the computation graph.
- Actions are typically used to collect results, write data to storage, trigger side effects, or perform aggregations and computations that require materializing the data.
Examples of actions include collect, count, take, reduce, saveAsTextFile, foreach, countByKey, foreachPartition, etc.
Here’s a simple analogy to understand the difference between transformations and actions:
- Transformations are like recipes in a cookbook. They specify how to transform raw ingredients (data) into a finished dish (new dataset) without actually cooking it.
- Actions are like turning on the stove and cooking the dish according to the recipe. They actually execute the transformations and produce a final result.